


はじめに:URLひとつで自分だけのレシピ帳を
「このレシピ動画、後で作ろう」と思ってブックマークしても、いざ料理するときに見返すのが面倒だったり、材料リストを作るのが手間だったりしませんか?
今回は、ノーコードAI開発ツール「Dify」と、万能データベース「Notion」を組み合わせて、レシピのURLやテキストを送るだけで、自動的に整理されたレシピデータベースを作成するシステムを構築します。
完成イメージ:こんなことができます
チャットボットにレシピサイトやYouTubeのURLを送信するだけで、AIが以下の情報を自動抽出し、Notionのデータベースに登録してくれます。
- レシピ名
- 材料(分量含む)
- 調理手順
- 調理時間
- ジャンル(タグ付け)

システム構成とDifyワークフローの全体像
このシステムは、以下のステップで処理を行います。
- 入力の分類: ユーザーが送ったのが「URL」か「テキスト」かをAIが判断します。
- 情報の抽出:
- Webサイトの場合:
Jina Readerなどのツールを使ってページ内容を取得。 - YouTubeの場合:字幕データ等から内容を取得。
- Webサイトの場合:
- データの構造化: 取得したテキストから、LLM(大規模言語モデル)が材料や手順を抜き出し、JSON形式に整形します。
- Notionへ登録: 整形されたデータをNotion API経由でデータベースに追加します。
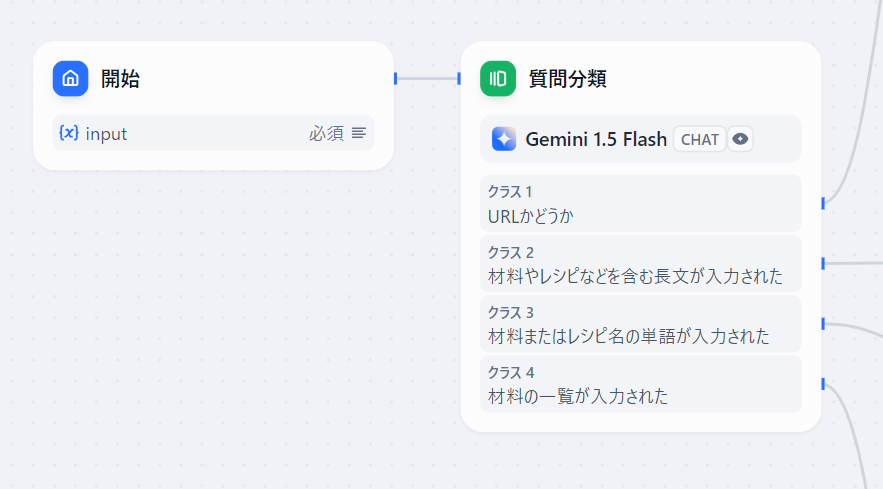
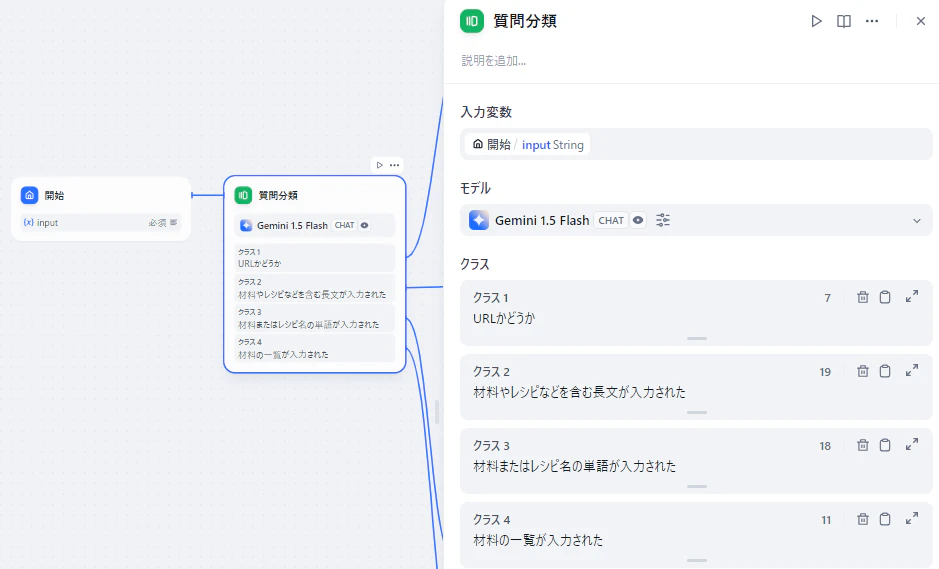
クラス1としてURLが入力された場合はURL内のテキストを、クラス2としてレシピが入力された場合はそのテキストを解析してNotionのAPIで登録できる形式に整形します。
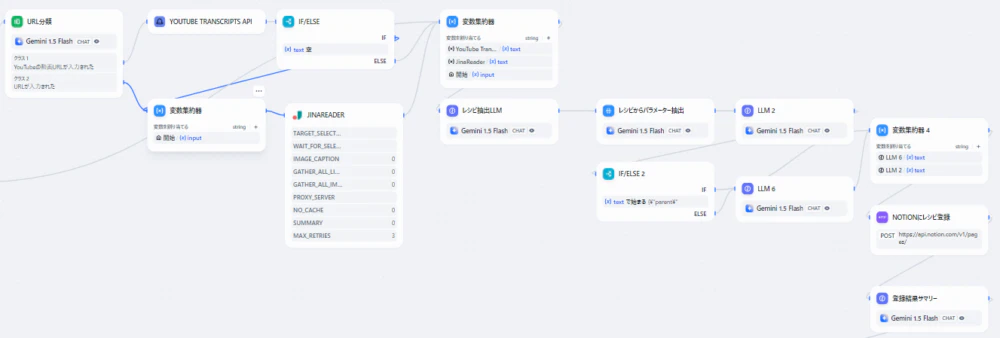
レシピ登録プロセス
ユーザー入力・質問分類
先述の通りユーザー入力をクラス1~4に分類して条件分岐します。
クラス2としてレシピのテキストが入力された場合は中間処理をスキップして変数集約器にぶち込みます。
URL解析
再度質問分類器を使用してYouTubeのURLかどうかで分岐しています。
Transcripts APIがあまり正常に動作しないので、空の場合はJinaReaderで処理されるようにフローを組んでいます。
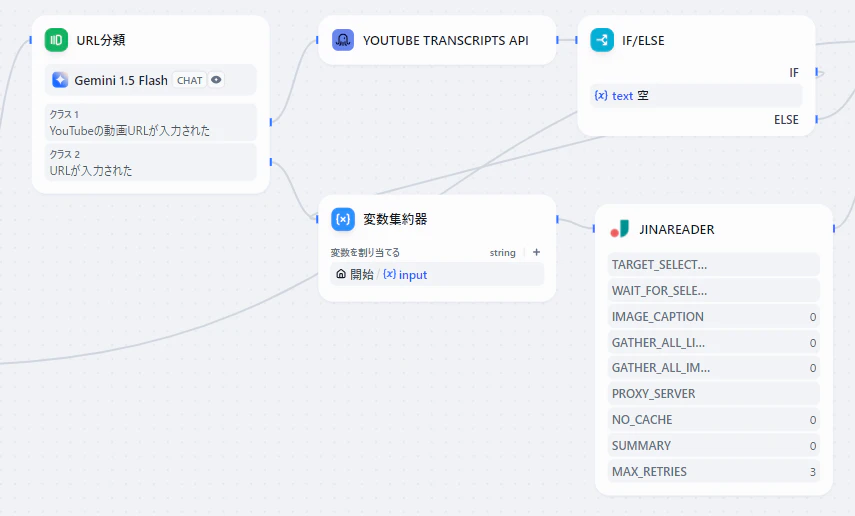
JinaReaderはURLの中のテキストを読み取ってくれるAPIで、無料で使えます。クオリティもいいです。
パラメータ抽出
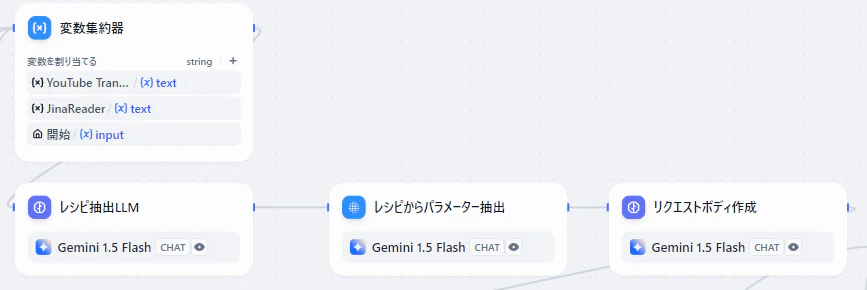
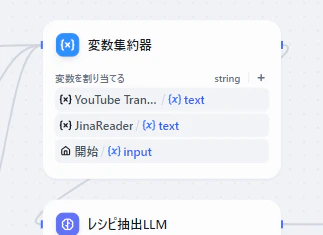
YouTube Transcript, Jinaまたはユーザー入力を変数集約器でまとめ、そのうち有効なものをレシピ抽出LLMでレシピを抽出します。

HTTPリクエストのボディは文字エスケープが面倒なのでLLMで成形してから入力します。
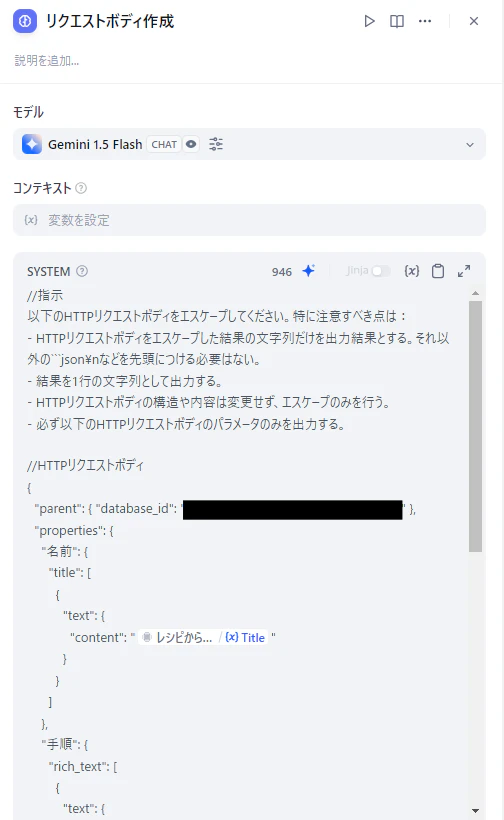
いくらプロンプトを工夫しても頭に”’jsonとついてしまうので、正しい形式になっていない場合は修正されるようにしています。現状エラー処理はIf/Elseで対応するしかなさそう。

Notion APIでレシピ登録
ここまででJSONを整形できたので、Notion APIでNotionにレシピを登録します。
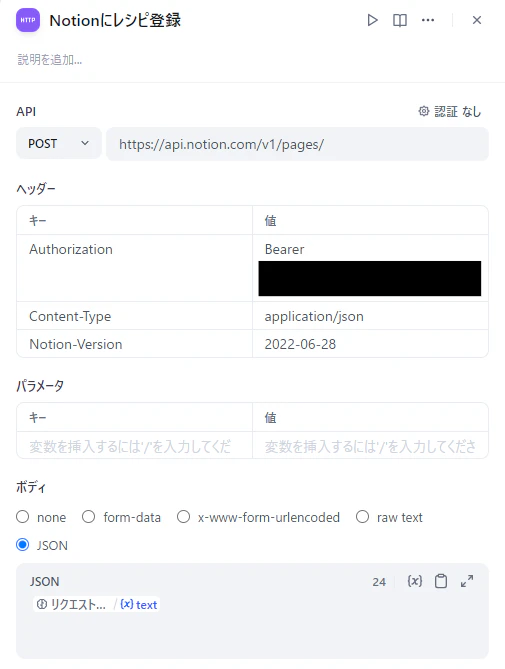
POST https://api.notion.com/v1/pages/
Authorization: Bearer [NOTION_API_KEY]
Content-Type: application/json
Notion-Version: 2022-06-28
ボディは以下の通りです。
{
"parent": { "database_id": "NOTION_DATABASE_ID" },
"properties": {
"名前": {
"title": [
{
"text": {
"content": "レシピ名"
}
}
]
},
"手順": {
"rich_text": [
{
"text": {
"content": "手順の詳細"
}
}
]
},
"材料": {
"rich_text": [
{
"text": {
"content": "材料の詳細"
}
}
]
},
"タグ": {
"multi_select": [
{ "name": "タグ1" },
{ "name": "タグ2" }
]
},
"時間": {
"number": 30
},
"URL": {
"url": "https://example.com/recipe"
}
}
}
構築のポイント:情報の抽出と整形
Webページからの情報取得(Jina Reader)
Webサイトのレシピを取り込む場合、スクレイピングツールとしてJina Readerを活用します。これにより、広告などの余計な情報を省き、レシピの核心部分(テキスト)だけを効率よくLLMに渡すことができます。
LLMによる構造化データへの変換
抽出したテキストデータはそのままではNotionに入れられません。LLMノードを使って、以下のようなJSONフォーマットに変換させます。
{ "name": "豚肉の生姜焼き", "ingredients": "豚ロース肉 200g, 生姜 1片...", "instructions": "1. 豚肉に小麦粉をまぶす...", "time": 20, "tags": ["和食", "定番", "豚肉"] }この工程を挟むことで、表記揺れを吸収し、データベースとして扱いやすいきれいなデータを作ることができます。
Notion API連携の設定
最後に、Difyの「HTTPリクエスト」ノードを使ってNotionにデータを送信します。
- URL:
https://api.notion.com/v1/pages - メソッド:
POST - ヘッダー: Authorization(APIキー)、Notion-Version
ボディ部分には、先ほどLLMで整形したデータをNotion APIの仕様に合わせて埋め込みます。
{ "parent": { "database_id": "YOUR_DATABASE_ID" }, "properties": { "Name": { "title": [{ "text": { "content": "{{name}}" } }] }, "Ingredients": { "rich_text": [{ "text": { "content": "{{ingredients}}" } }] }, "Tags": { "multi_select": [ { "name": "{{tag1}}" }, { "name": "{{tag2}}" } ] } } }まとめ:業務システムへの応用も可能
今回は「レシピ管理」をテーマにしましたが、この「URLや非構造データから情報を抽出し、データベースに登録する」という仕組みは、様々なビジネスシーンに応用可能です。
- 競合調査: ニュース記事のURLから企業名や動向を抽出してリスト化
- 採用管理: 応募メールやPDFの職務経歴書からスキルを抽出してDB化
- 問い合わせ対応: メールの内容を要約・分類して管理台帳に登録
DifyとNotionの連携で、身の回りの「情報整理」を自動化してみてはいかがでしょうか。
【推奨】業務システム化に有効なアイテム
生成AIを学ぶ



システム化のパートナー(ミラーマスター合同会社)




VPSサーバの選定



コメント