

「競合サイトの価格情報を一覧にしたい」
「ブログ記事のタイトルとURLをまとめて取得したい」
そんな時、プログラミングができなくてもGoogleスプレッドシートさえあれば、簡単にWeb上のデータを収集(スクレイピング)できることをご存知でしょうか?
この記事では、エンジニアでなくてもできる、スプレッドシート関数を使ったお手軽スクレイピング術をご紹介します。
スクレイピングの主役:IMPORTXML関数
Googleスプレッドシートには、Webページから特定のデータを抜き出すための神関数「IMPORTXML」が存在します。
=IMPORTXML(URL, XPathクエリ)使い方は非常にシンプルです。
- 第一引数(URL): データを取得したいWebページのURL
- 第二引数(XPath): ページの「どの部分」を取得するかを指定するパス
この「XPath(エックスパス)」さえ分かれば、タイトルでも価格でも、自在にデータを抽出できます。
ChromeでXPathを簡単に取得する方法
「XPathなんて書けない!」という方も安心してください。
Google Chromeの標準機能を使えば、クリックだけでXPathを取得できます。
手順1:デベロッパーツールを開く
データを取得したいWebページを開き、取得したい箇所(例:記事タイトル)の上で右クリック → 「検証」を選択します。
手順2:XPathをコピーする
デベロッパーツール(検証画面)で該当のHTMLタグがハイライトされます。
そのタグの上で右クリック → 「Copy」 → 「Copy XPath」を選択します。
これで、クリップボードに//*[@id="main"]/div...のようなコードがコピーされました。
これがXPathです。
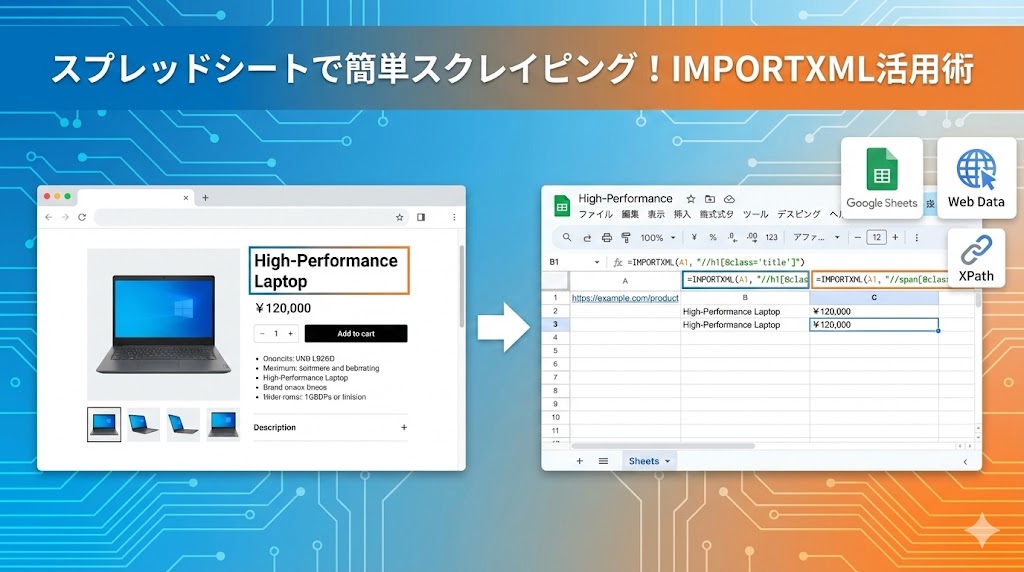
実践:記事リストを自動取得してみよう
では実際に、スプレッドシートに入力してみましょう。
- A1セルに、取得したいページのURLを入力します。
- B1セルに、以下の関数を入力します。 (※コピーしたXPathの中にあるダブルクォーテーション
"は、シングルクォーテーション'に書き換えてください)
=IMPORTXML(A1, "//*[@id='main']/.../h2/a")これだけで、ページ内の該当するデータ(例:記事タイトル一覧)がズラッと表示されます。
知っておくと便利な補助関数
取得したデータをさらに活用するために、以下の関数も組み合わせて使うのがおすすめです。
1. ARRAYFORMULA(配列数式)
取得したデータを加工(例えば日付形式を変更)しようとすると、1行しか表示されないことがあります。
そんな時は、式の先頭にARRAYFORMULAをつけることで、全行に対して処理を適用できます。
2. IMAGE(画像表示)
画像URL(src属性)を取得した場合、=IMAGE(URL)関数を使うことで、セルの中に画像そのものを表示させることができます。
3. SPLIT & JOIN(分割と結合)
タグ情報などが「カンマ区切り」で欲しい場合や、逆に「バラバラのセル」に分けたい場合に便利です。
- JOIN: 複数のセルを結合する(例:タグをカンマ区切りにする)
- SPLIT: 文字列を特定の記号で分割する
まとめ:スプレッドシートで情報収集を自動化しよう
プログラミング言語(Pythonなど)を使わなくても、スプレッドシートだけでかなりのレベルまでスクレイピングが可能です。
市場調査や競合分析、コンテンツ管理など、日々の業務効率化にぜひ役立ててください。
注意点:
スクレイピングを行う際は、相手方サーバーへの負荷に配慮し、利用規約(Robots.txtなど)を確認した上で行いましょう。
【推奨】業務システム化に有効なアイテム
生成AIを学ぶ



システム化のパートナー(ミラーマスター合同会社)




VPSサーバの選定



コメント