

「サーバー管理なしでコードを実行したい」
「AIサービスと連携したバックエンドをサクッと作りたい」
そんな時に活躍するのがAWS Lambdaです。この記事では、AWSコンソール上でのLambda関数の作成から、Python (Boto3) を使って生成AIサービス「Amazon Bedrock Knowledge Base」に質問を投げる機能を実装するまでの手順をステップバイステップで解説します。
AWS Lambdaとは?
AWS Lambdaは、サーバーのプロビジョニングや管理を行わずにコードを実行できるコンピューティングサービスです。必要な時だけコードが実行され、使用したコンピューティング時間に対してのみ料金が発生するため、コスト効率が良く、スケーラブルなアプリケーション構築に最適です。
開始するには、「最初の関数を作成する」を参照してください。
Lambda を使用する際、ユーザーが責任を負うのはコードのみです。Lambda は、高可用性コンピューティングインフラストラクチャ上でコードを実行し、サーバーとオペレーティングシステムのメンテナンス、容量のプロビジョニングと自動スケーリング、コードのモニタリング、ログ記録などのすべてのコンピューティングリソースを管理します。
実践:Bedrock連携Lambda関数の作成
今回は、Amazon Bedrockのナレッジベース(Knowledge Base)に対して質問を行い、回答を取得するLambda関数をPythonで作成します。
1. Lambda関数の作成と基本設定
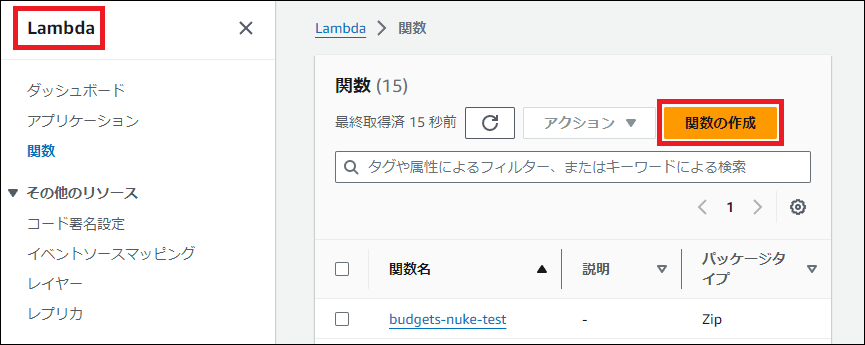
- AWSコンソールでLambdaを開き、「関数の作成」をクリックします。
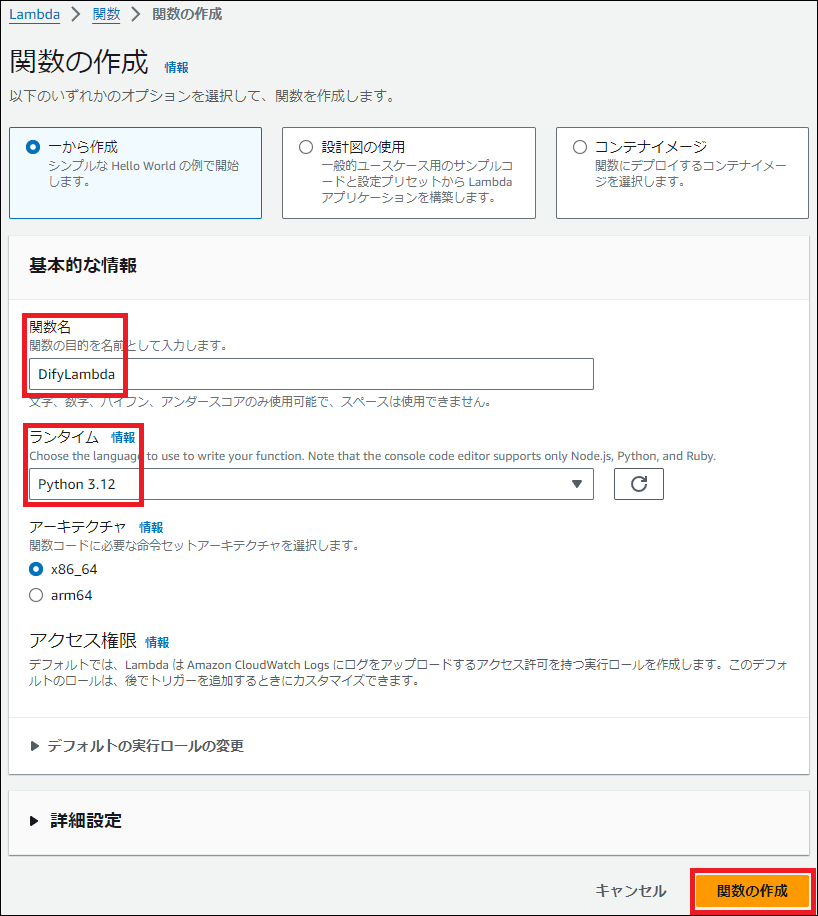
- 「一から作成」を選択し、関数名(例:
ask-bedrock-kb)を入力、ランタイムはPython 3.xを選択します。 - 「関数の作成」ボタンを押します。
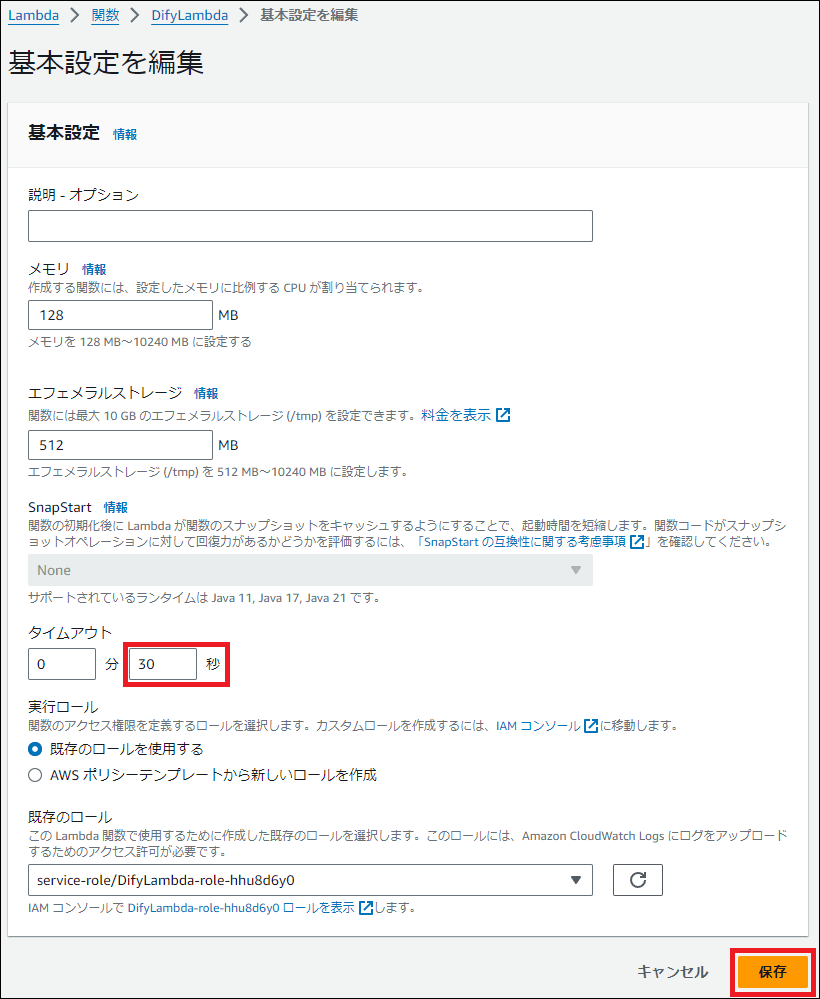
2. タイムアウトと環境変数の設定
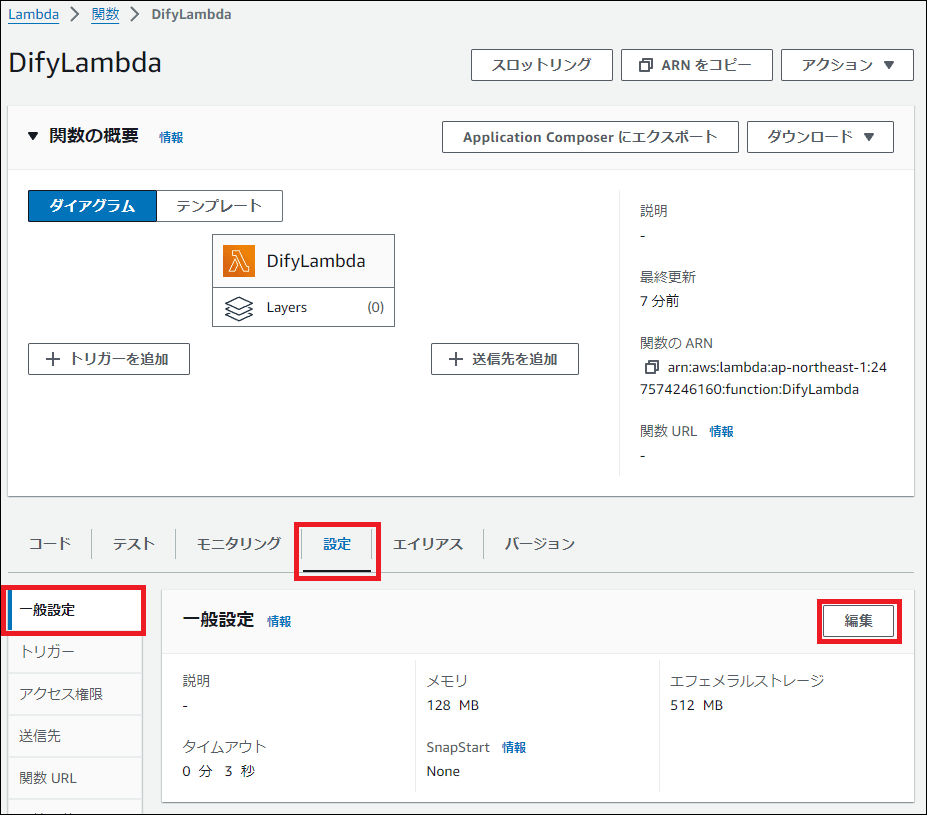
AI処理は時間がかかる場合があるため、タイムアウト時間を延長します。「設定」タブ → 「一般設定」から、タイムアウトを30秒に変更します。
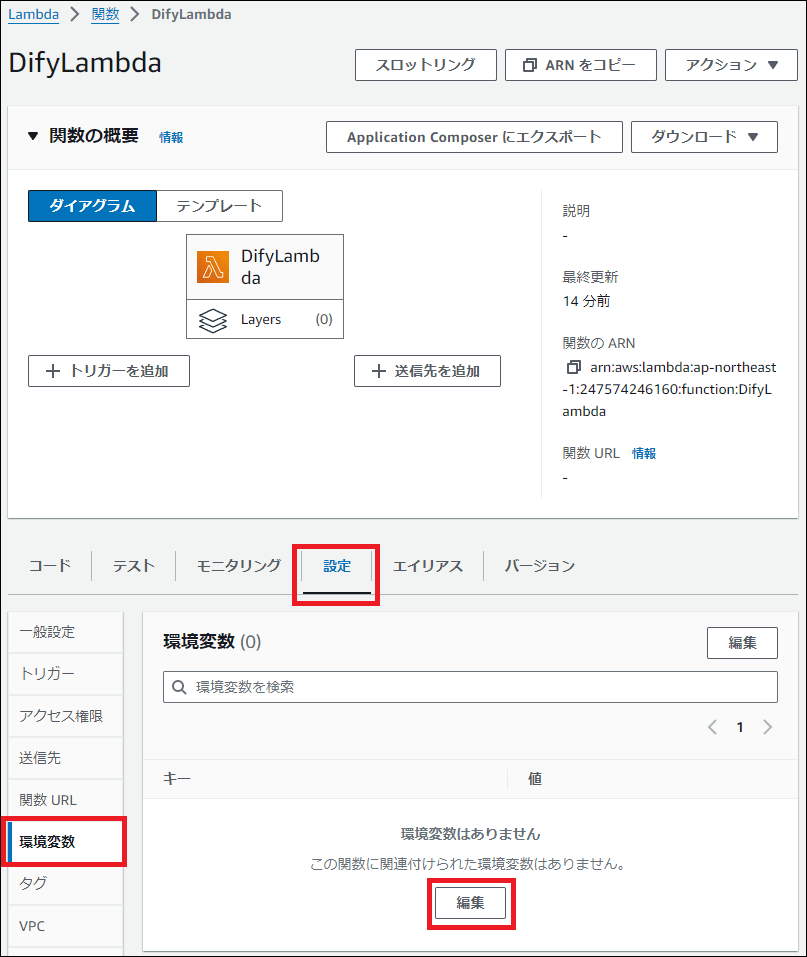
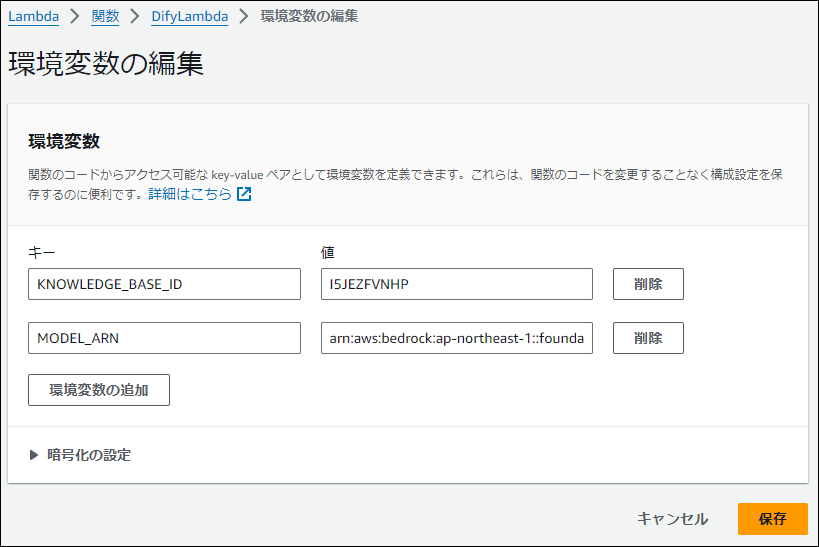
次に、「環境変数」を設定します。コード内で使用する以下の値を登録してください。
| キー | 値(例) |
|---|---|
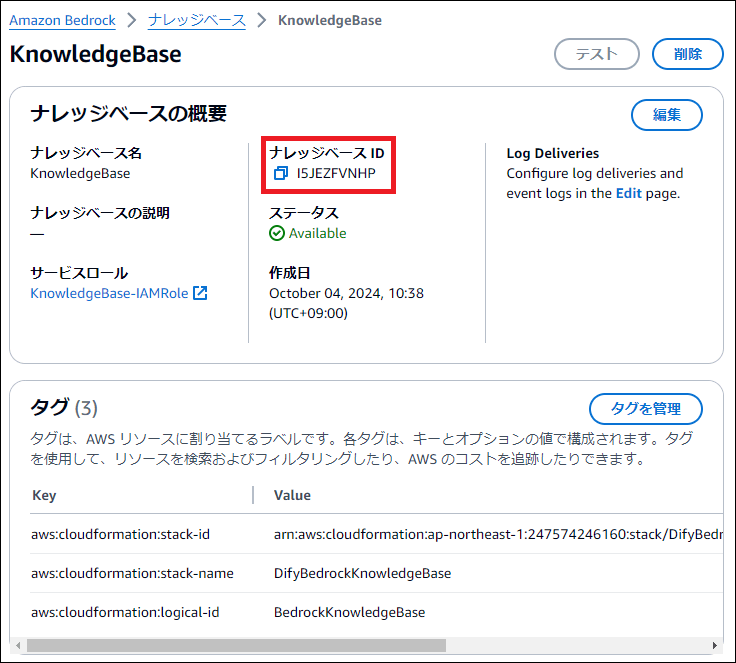
| KNOWLEDGE_BASE_ID | (Bedrock Knowledge Base IDを入力) |
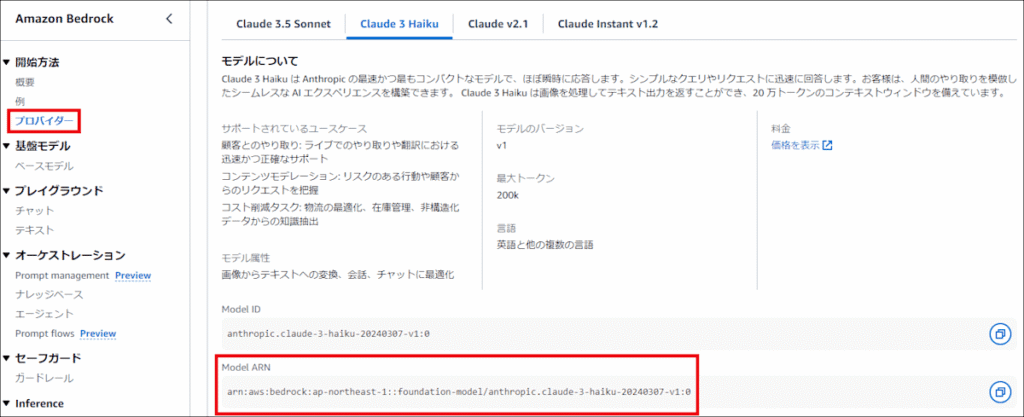
| MODEL_ARN | arn:aws:bedrock:ap-northeast-1::foundation-model/anthropic.claude-3-haiku-20240307-v1:0 |
3. IAM権限の追加
LambdaがBedrockにアクセスできるように、実行ロールに権限を追加します。
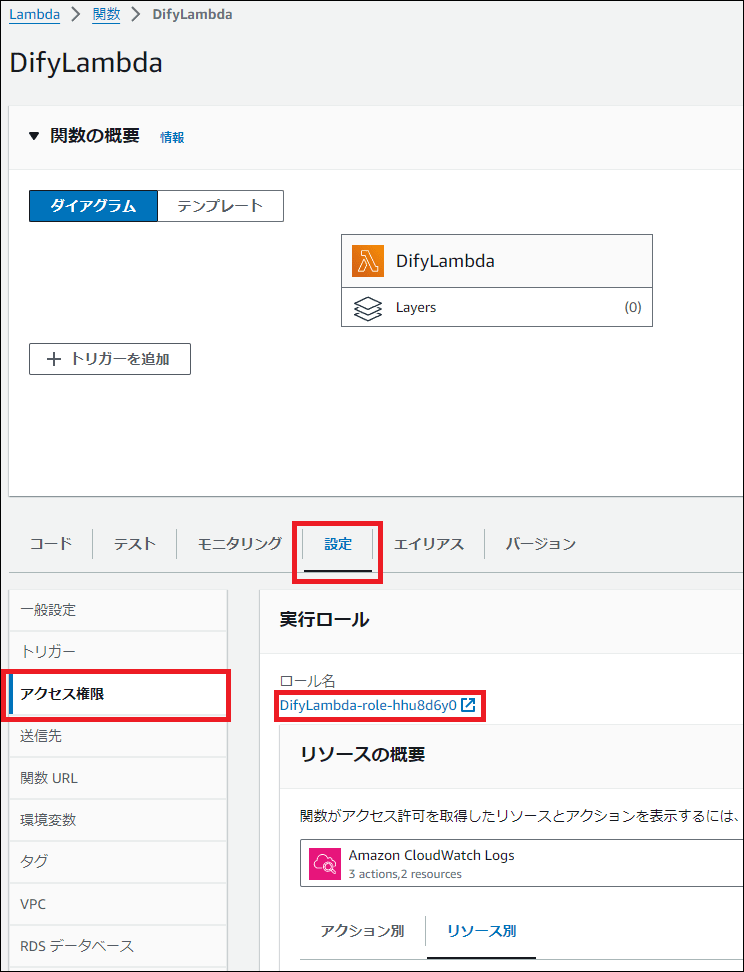
- 「設定」タブ → 「権限」から、実行ロール名をクリックしてIAMコンソールを開きます。
- 「許可を追加」→「ポリシーをアタッチ」を選択し、
AmazonBedrockFullAccessを検索して追加します。
※KNOWLEDGE_BASE_IDの確認方法
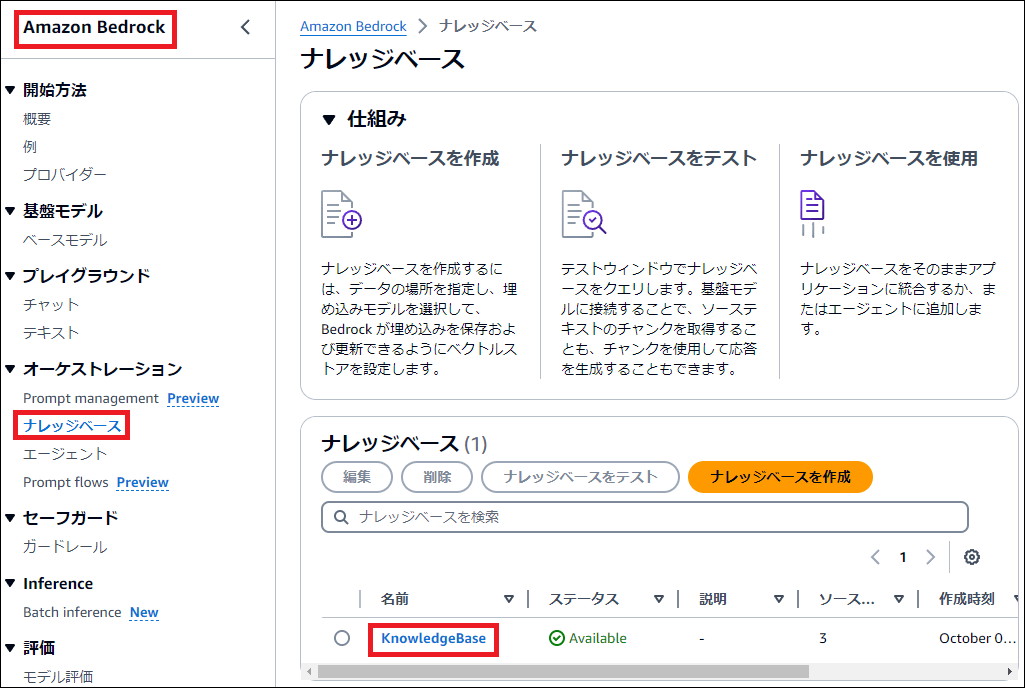
※MODEL_ARNの確認方法 (テキストモデルの Claude 3 Haiku を使用します)
Lambda の IAM Role に、Bedrock へのアクセス権限を追加します
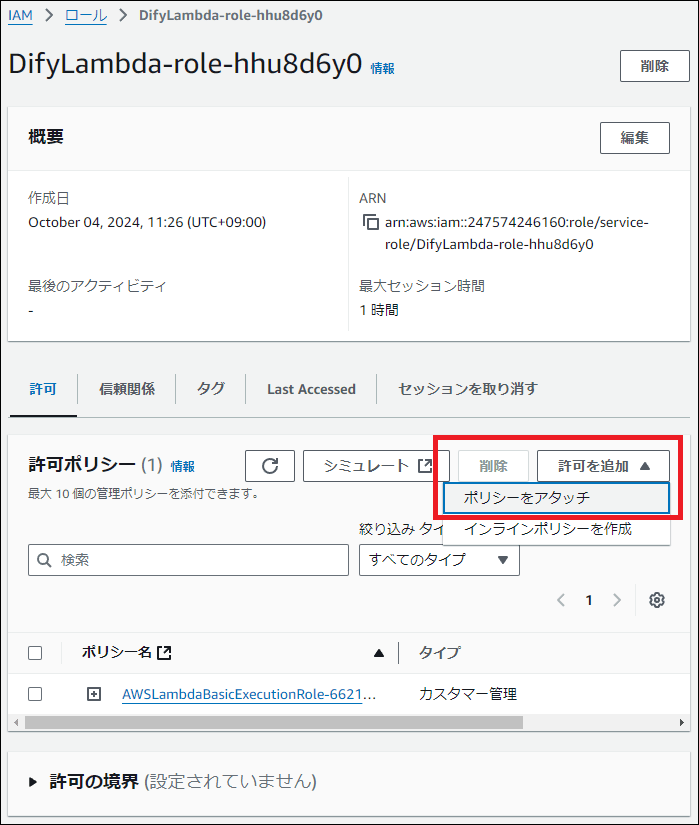
以下の IAM Policy を追加します
AmazonBedrockFullAccess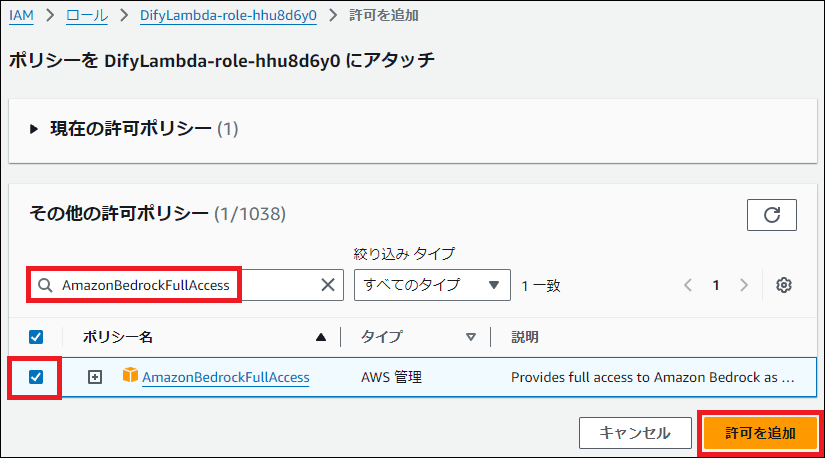
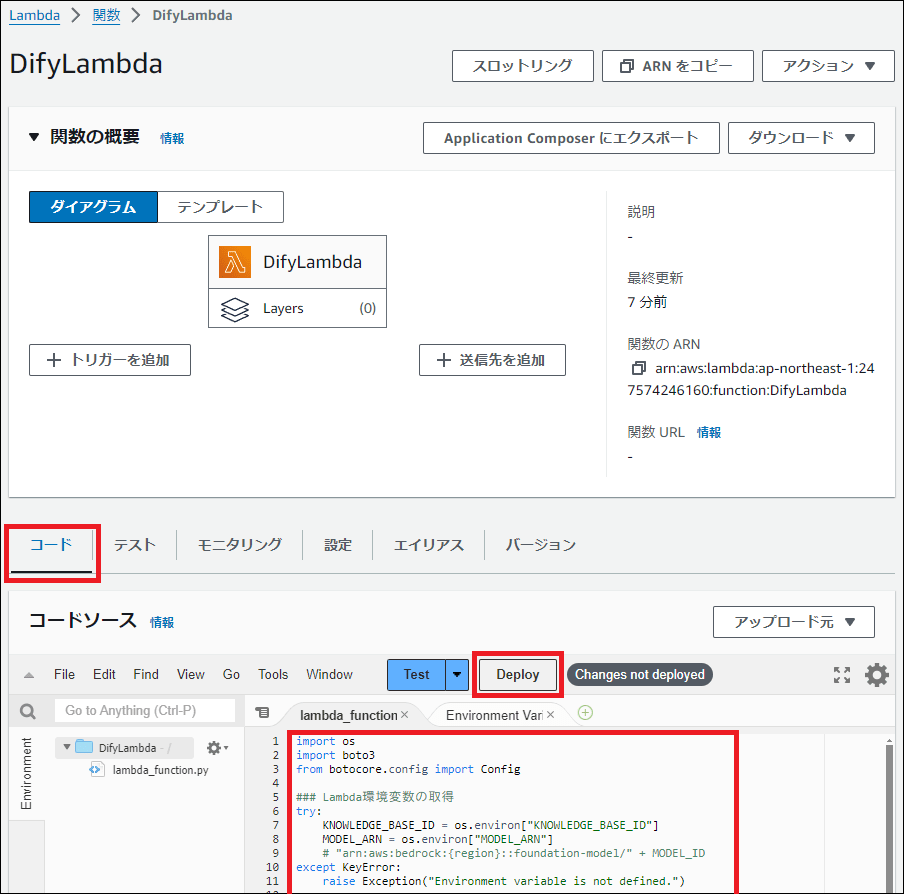
4. コードの実装とデプロイ
「コード」タブに戻り、lambda_function.pyに以下のコードを貼り付けます。
import os import boto3 from botocore.config import Config
環境変数の取得
KNOWLEDGE_BASE_ID = os.environ.get("KNOWLEDGE_BASE_ID") MODEL_ARN = os.environ.get("MODEL_ARN")
Bedrock Agent Runtime クライアントの初期化
config = Config( retries={"max_attempts": 30, "mode": "standard"}, read_timeout=900, connect_timeout=900, ) bedrock_agent_runtime_client = boto3.client("bedrock-agent-runtime", config=config)
def lambda_handler(event, context): try: query = event.get("query") if not query: return {"statusCode": 400, "body": "Query is required"}
# Bedrock Knowledge Base に質問を送信
response = bedrock_agent_runtime_client.retrieve_and_generate(
input={"text": query},
retrieveAndGenerateConfiguration={
"type": "KNOWLEDGE_BASE",
"knowledgeBaseConfiguration": {
"knowledgeBaseId": KNOWLEDGE_BASE_ID,
"modelArn": MODEL_ARN,
"retrievalConfiguration": {
"vectorSearchConfiguration": {"numberOfResults": 3},
},
},
},
)
# 回答テキストを抽出
output_text = response['output']['text']
return {"statusCode": 200, "body": output_text}
except Exception as e:
print(f"Error: {e}")
return {"statusCode": 500, "body": str(e)}コードを貼り付けたら、「Deploy」ボタンを押して保存します。
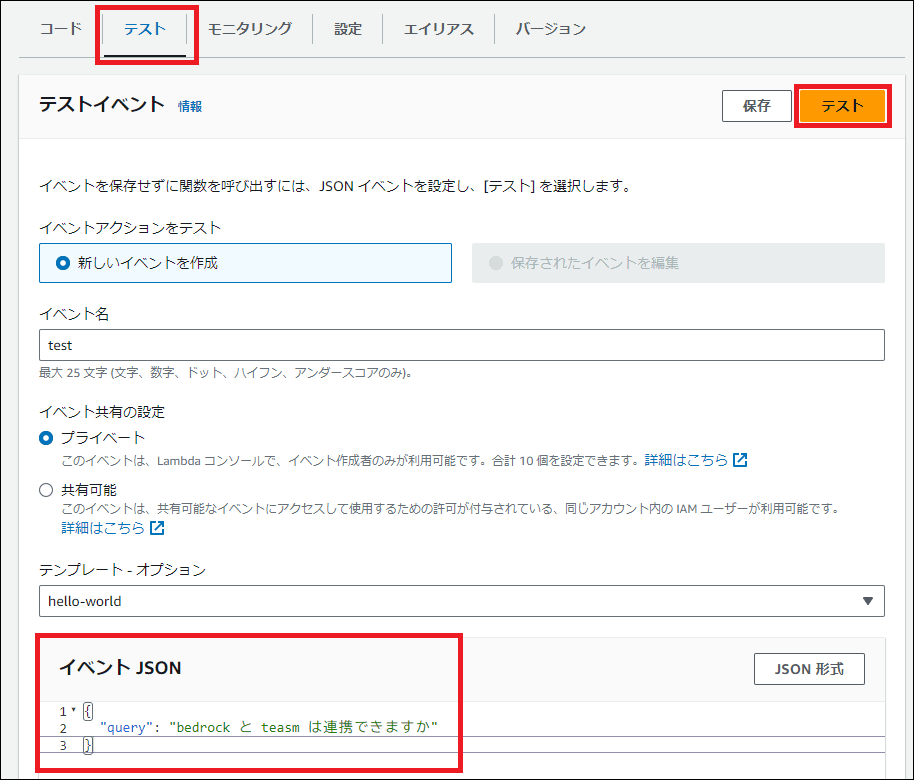
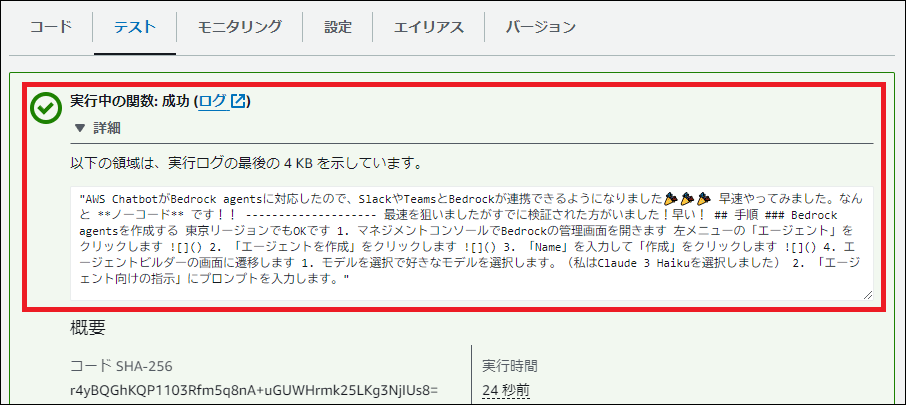
5. 動作テスト
「Test」タブで新しいテストイベントを作成し、以下のJSONを入力して「Test」ボタンをクリックします。
{ "query": "bedrock と teams は連携できますか" }実行結果にBedrockからの回答が表示されれば成功です!
まとめ
これで、AWS Lambdaを使って生成AI(Bedrock)と連携するバックエンド処理が完成しました。
このLambda関数をAPI Gatewayと組み合わせることで、Webアプリや外部ツール(Difyなど)から簡単に呼び出せるAI APIとして公開することが可能になります。
コメント