


Difyを使えば、高性能なAIチャットボットをノーコードで簡単に作成できます。
しかし、AIモデルはあくまで「インターネット上の公開情報」を学習したものであり、あなたの会社の「社内規定」や「非公開のプロジェクト情報」については何も知りません。
無理に答えさせようとすれば、もっともらしい嘘(ハルシネーション)をつくリスクさえあります。
これを解決し、AIに「自社の知識」を持たせる技術が「RAG(Retrieval-Augmented Generation)」です。
この記事では、Difyにおけるナレッジベースの構築方法、最適な設定、そして設定の違いによる回答精度の比較検証までを徹底解説します。
RAGとナレッジベースの基礎知識
RAG(検索拡張生成)とは?
RAGとは、ユーザーの質問に対し、あらかじめ用意した「知識ベース(ナレッジベース)」から関連情報を検索し、その情報を元にAIが回答を作成する技術です。
この「検索」は、単なるキーワード一致ではありません。
文章の意味や文脈を理解するために、データを「ベクトル(数値)」に変換し、質問との「類似度」が高い情報を取り出して使用します。
情報のベクトル化
AIが理解できる形式(数値)に情報を変換することを「ベクトル化」と言い、その役割を担うのが「埋め込みモデル(Embedding Model)」です。
ベクトル化により、質問との類似度が高い情報を迅速に見つけることが可能となります。
Dify で ベクトル化 できる情報は次のとおりです。
- テキストファイル:
.txt - Markdownファイル:
.md - PDFファイル:
.pdf - HTMLファイル:
.html - Excelファイル:
.xlsx,.xls - Wordファイル:
.docx - CSVファイル:
.csv
など
OpenAIが提供する代表的な埋め込みモデルの性能とコスト比較は以下の通りです。
| モデル名 | 料金 (1000トークンあたり) | 性能 (平均スコア) |
|---|---|---|
| text-embedding-3-large | $0.00013 | 54.9% |
| text-embedding-3-small | $0.00002 | 44.0% |
| text-embedding-ada-002 | $0.00010 | 31.4% |
結論: コストパフォーマンスを重視するなら text-embedding-3-small が最適解です。前世代のモデルより高性能でありながら、コストは5分の1に抑えられています。
チャンク(情報の分割)の重要性
長いドキュメントをそのままAIに渡すことはできません。
Difyは情報を「意味のある小さな塊(チャンク)」に分割して保存します。このサイズ設定が回答精度を左右します。
分割するサイズを変更することもできますが、不用意に変更すると回答精度の低下を招きます。
分割するサイズが小さすぎる
文脈が分断され、AIが意味を正しく理解できません。
適正な分割サイズ
文脈を保持しつつ、必要な情報だけをピンポイントで検索可能です。
分割するサイズが大きすぎる
検索結果に無関係な情報が混ざり、回答の精度が下がります。
実践:ナレッジベースの構築手順
ここからはDifyを使って実際にナレッジベースを構築します。
今回は比較検証のため、以下の2種類を作成します。
- 経済的ナレッジベース:埋め込みモデルを使わず、キーワード検索のみを行う(低コスト・低精度)。
- 高品質ナレッジベース(推奨):埋め込みモデルを使用し、ベクトル検索を行う(高精度)。
STEP 1:空のナレッジベースを作成
ナレッジ画面から「空のナレッジベースを作成」を選択し、名前と説明を入力します。
STEP 2:ドキュメントのアップロード
用意した社内文書(例:就業規則.docx)をアップロードします。
「テキストファイルをアップロード」にファイルをドラッグ&ドロップします。

STEP 3:チャンクと検索の設定(重要)
ここが精度の分かれ道です。「高品質ナレッジベース」を目指す場合、以下の設定を推奨します。
| 項目 | 推奨設定 |
|---|---|
| チャンク設定 | カスタム |
| 最大チャンク長 | 400 〜 500 トークン |
| オーバーラップ | 50 トークン |
| 埋め込みモデル | text-embedding-3-small |
| 検索設定 | ハイブリッド検索 |
| 項目 | 説明 |
|---|---|
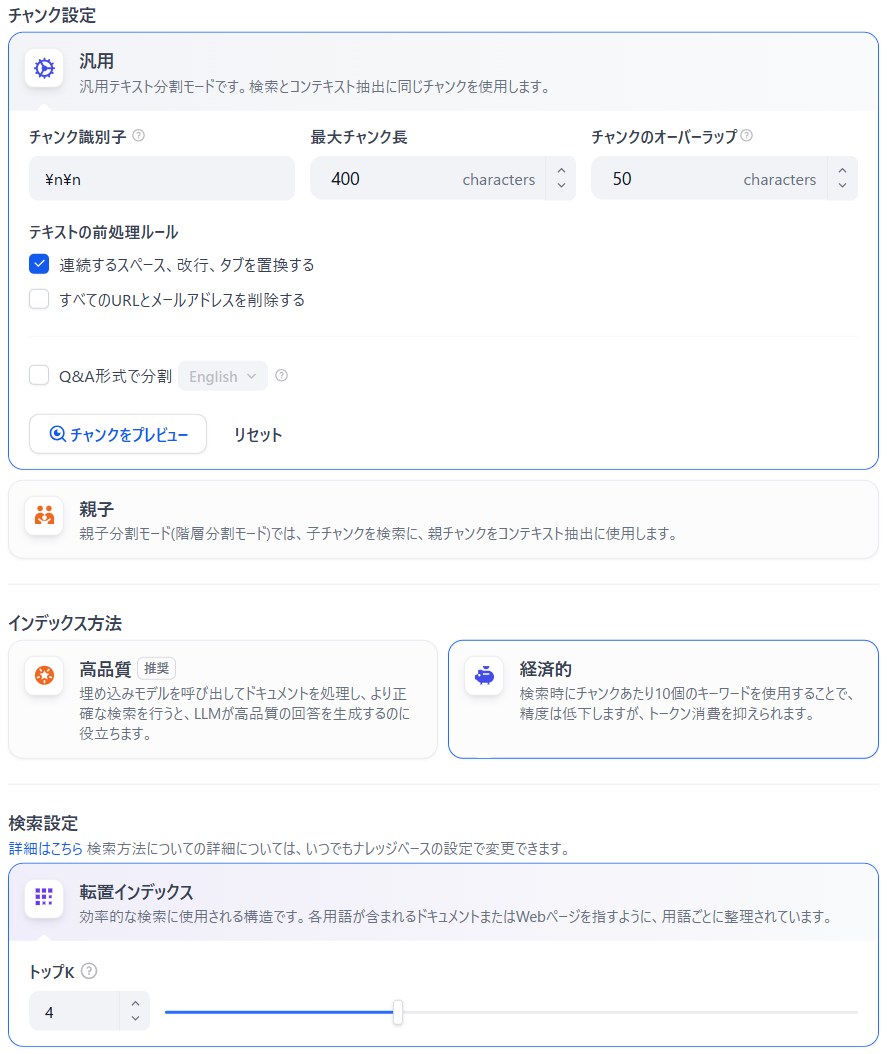
| チャンク識別子 | テキスト分割に使用する区切り文字です。 連続する2個の改行を区切りとします。 |
| 最大チャンク長 | チャンクサイズ(文字数またはトークン数)に 400 を設定します。 |
| チャンクのオーバーラップ | 隣接するチャンク同士で重複する部分のサイズ(文字数またはトークン数)です。 50 を設定します。 |
| 連続するスペース、改行、タブを置換する | スペース・改行・タブ文字を除去します。 チェックしておきます。 |
| すべてのURLとメールアドレスを削除する | URL とメールアドレスを除去します。 未チェックにしておきます。 |
| Q&A形式で分割 | 情報ファイルをQ&A形式(「”Q”と”A”」や「”質問”と”回答”」など)で分割します。 未チェックにしておきます。 |
| 項目 | 説明 |
|---|---|
| トップK | 検索結果の上位 K個 のチャンクを使用します。 4 を推奨します。 |
「保存して処理」をクリックすると、ドキュメントのベクトル化が開始されます。
精度比較検証:経済的 vs 高品質
実際に作成した2つのナレッジベースに対し、Geminiモデルを使って同じ質問を投げかけ、回答精度を比較しました。
検証結果のまとめ
1. 経済的ナレッジベース(キーワード検索のみ)
- 検索精度が低く、質問の意図と異なる箇所を参照してしまうケースが見られた。
- コストは抑えられるが、業務利用には信頼性が不足する可能性がある。
2. 高品質ナレッジベース(ハイブリッド検索)
- ベクトル検索の効果により、質問の意図に近い情報を的確に抽出できた。
- Gemini 2.5 Flashなどの最新モデルと組み合わせることで、より自然で人間らしい回答が得られた。
結論:ビジネス利用なら「ハイブリッド検索」一択
検証の結果、キーワード検索のみの「経済的設定」では、AIが的確な回答を行うのが難しいことが分かりました。
業務システムとして導入する場合、多少のコストがかかっても「ハイブリッド検索(ベクトル+キーワード)」を採用すべきです。
さらに精度を高めたい場合は、検索結果を再ランク付けする「Rerankモデル」の導入も検討すると良いでしょう。
Difyのナレッジ機能を正しく設定し、あなたの会社専用の「賢いAI」を育てていきましょう。
【推奨】業務システム化に有効なアイテム
生成AIを学ぶ



システム化のパートナー(ミラーマスター合同会社)




VPSサーバの選定



コメント