


「ChatGPTは便利だけど、自社の製品情報や社内ルールについては答えてくれない…」
「PDFやWebサイトの情報をAIに読み込ませて、賢いFAQチャットボットを作りたい!」
もしあなたがそう考えているなら、Difyの「RAG(ラグ)」機能がその悩みを解決します。
この記事では、AI初心者の方でも安心して取り組めるよう、「RAGとは何か?」という基本から、Difyでの具体的な設定手順、そしてAIの回答精度をさらに高めるためのコツまで、ステップバイステップで徹底的に解説します。
第1章:RAGとは何か? – AIの「弱点」を克服する魔法の技術
まず、RAGがなぜ必要なのかを理解しましょう。一般的なAIは、インターネット上の膨大な情報を学習していますが、「あなたの会社の社内規定」や「昨日発売されたばかりの新製品情報」などの限定的な情報は知りません。
- 知らないことは答えられない:あなたの会社の社内規定や、昨日発売されたばかりの新製品情報など、限定公開の情報や最新すぎる情報は知りません。
- 嘘をつくことがある(ハルシネーション):知らない情報について質問されると、もっともらしい嘘の情報を生成してしまうことがあります。
RAG(Retrieval-Augmented Generation:検索拡張生成)は、この弱点を克服する技術です。
仕組みは非常にシンプルで、AIに「カンニングペーパー(自社の資料)」を渡して、それを見ながら回答させる技術だと考えてください。
するのが**RAG(Retrieval-Augmented Generation:検索拡張生成)**です 。難しく聞こえますが、仕組みは非常にシンプルです。
- Retrieval(検索):ユーザーから質問が来たら、まずAIが学習していない外部のデータベース(あなたが用意した社内文書やWebサイトなど)から、関連性の高い情報を探し出します。
- Augmented(拡張):探し出した情報を「カンペ」として、ユーザーの質問と一緒にAIに渡します。
- Generation(生成):AIは、その「カンペ」の内容に基づいて、正確な回答を生成します。
つまりRAGとは、AIに「自社の資料を検索して、その内容だけを参考にして答えてね」とお願いする技術なのです。Difyでは、このRAGを実現するための機能を「ナレッジ」と呼んでいます 。
第2章:ステップ1 – AIの教科書を作る「ナレッジベースの作成」
それでは、実際にDifyでRAGを構築していきましょう。最初のステップは、AIに学習させたい情報を登録することです。
1. 「ナレッジ」を作成する
Difyの管理画面上部にあるメニューから「ナレッジ」を選択し、「ナレッジベースを作成」ボタンをクリックします。
2. ファイルをアップロードする
学習させたい資料(PDF、Word、Excel、テキストファイルなど)をアップロードします。
Difyはアップロードされた文書を自動的に「チャンク(小さな塊)」に分割し、「ベクトル化(数値化)」してAIが読める形に変換してくれます。
① チャンキング(情報の分割)
AIは一度に長すぎる文章を読むのが苦手です。そのため、Difyはアップロードされた文書を、意味のある小さな塊(チャンク)に自動で分割します 。この分割方法は、通常は「自動モード」で問題ありませんが、「カスタムモード」でチャンクのサイズなどを調整することも可能です 。
② ベクトル化(情報の数値化)
AIは人間の言葉をそのまま理解できません。そのため、分割されたチャンクを「ベクトル」と呼ばれる数値の羅列に変換します 。これは、言葉の意味をAIが理解できる形式に「翻訳」する作業だと考えてください。この処理は「埋め込みモデル」という専門のAIが担当します。
ナレッジベースは以下の内容から作成することが可能です。
- ファイルからインポート:PDF、Word、Excel(CSV)、テキストファイルなどを直接アップロードできます。最も手軽で一般的な方法です。
- Notionから同期:普段使っているNotionのページを、そのままナレッジとして連携できます。
- Webサイトから同期:会社のヘルプページや製品サイトのURLを指定すると、その内容を自動で読み込んでくれます。
第3章:ステップ2 – アプリケーションとナレッジを連携させる
教科書ができたので、次はこの教科書をAIチャットボットに持たせて、実際に使えるように連携させます。
1. 「知識検索」ノードを追加する
チャットフロー作成画面で、「開始」ノードと「LLM」ノードの間に「知識検索(Knowledge Retrieval)」ノードを追加します。

2. ナレッジを紐付ける
「知識検索」ノードの設定で、先ほど作成したナレッジベースを選択します。
3. プロンプトで指示を出す
LLMノードのプロンプト欄に、以下のように記述します。
{{knowledge}} という変数が重要です。ここに検索結果が自動的に挿入されます。
# 指示 提供された参考資料「{{knowledge}}」の内容だけを厳密に参照し、ユーザーからの質問「{user_input}」に回答してください。
制約
資料に書かれていないことは、絶対に推測で回答しないでください。第4章:ステップ3 – RAGの精度をさらに高める応用テクニック
回答の精度を劇的に向上させるための「Rerank(リランク)」設定について解説します。
ハイブリッド検索 + Rerankモデル
「知識検索」ノードの設定で、以下の組み合わせにするのが最強の構成です。
- 検索設定:「ハイブリッド検索」(キーワード一致と意味検索の両方を行う)
- Rerankモデル:「有効化」する
「知識検索」ノードの設定には、以下項目があります 。
- ベクトル検索:言葉の「意味」の近さで検索します。キーワードが完全に一致しなくても、関連性の高い内容を見つけ出せます。
- 全文検索:キーワードがそのまま含まれているかを検索します。製品の型番など、固有名詞の検索に強いです。
- ハイブリッド検索:上記2つを組み合わせた、最も強力で推奨される検索方法です。
通常は「ハイブリッド検索」を選択しておけば問題ありません。
Rerank(リランク)とは?
検索で見つかった複数の候補の中から、「本当に質問に関係あるもの」をAIが再審査して並び替える機能です。
これを利用するには、CohereなどのRerankモデル提供プロバイダーのAPIキー設定が必要です。
どこのプロバイダーがRerank用のモデルを提供しているのかについては、下記の赤線部分を見れば分かります。

提供しているプロバイダーの数はそれ程多くはありません。迷ったならCohereを選択するといいようです。Cohereが提供しているモデルが一番精度が高くて有名なためです。Cohereのモデルは無償で提供されています。
「rerank-v3.5」は最新のモデルで、多言語にも対応しています。当然日本語にも対応しています。
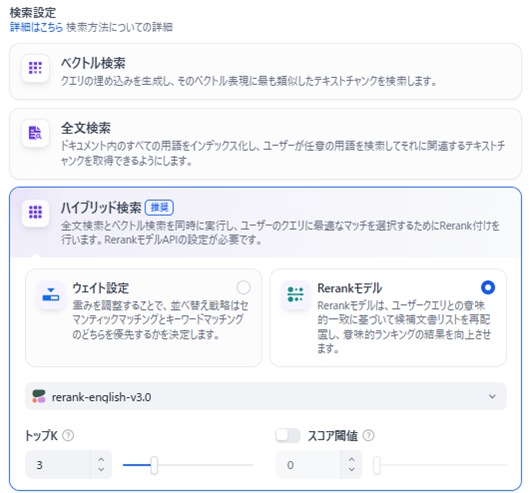
ウェイト設定
ウェイト設定のウェイトとは重みのことです。なぜか訳を「重み設定」とせずに「ウェイト設定」と訳しています。何のウェイトかといえば、ベクトル検索で使われる「セマンティック優先度」と、全文検索で使われる「キーワード優先度」のこととなります。単にベクトル検索と全文検索を行うだけでなく、ウェイトを考慮した上で検索した方が、精度をあげることができます。
セマンティック優先度とキーワード優先度の重みの付け方は諸刃の剣です。つまり、セマンティック優先度を高く設定すれば、キーワード優先度は低くなり、逆にセマンティック優先度を低く設定すれば、キーワード優先度は高くなります。
Rerank設定
精度をよくしたい場合は、「ウェイト設定」ではなく「Rerank設定」をすることになります。ウェイト設定よりもRerank設定の方が検索の精度が高くなります。Rerank設定にすれば、重みを付けたハイブリッド検索は行ってくれないが、その代わりに、再順位付けを行うようになります。
まとめ:あなただけの専門家AIを育てよう
DifyのRAG機能を使えば、プログラミング知識がなくても、自社のマニュアルやノウハウを完璧に理解したAIアシスタントを作成できます。
ぜひ、このガイドを参考に、業務効率化を実現する「最強のAIパートナー」を育ててみてください。
【推奨】業務システム化に有効なアイテム
生成AIを学ぶ



システム化のパートナー(ミラーマスター合同会社)




VPSサーバの選定



コメント